Daniel Binns is a media theorist and filmmaker tinkering with the weird edges of technology, storytelling, and screen culture. He is the author of Material Media-Making in the Digital Age and currently writes about posthuman poetics, glitchy machines, and speculative media worlds.
It’s been an enormous year. Huge strides in terms of my academic identity and specialisation, a rejuvenation of creative practice, worldbuilding, storytelling, and two semesters of teaching across undergrad and postgrad.
More than anything, though, this year has been characterised by a deliberate choice to open up my research, creativity, practice, and weirdo critical-creative play. I’ve delivered ten talks, presentations, papers, facilitated four extended workshops on glitch AI methods, and two guest lectures on AI and media futures. I’ve also published about a dozen blogs/posts on my ongoing work, research, projects.
This sharing has been incredibly daunting: it’s not my default mode at all. And it can be scary to talk about work that is barely in progress, but rather in a constant state of flux and flow. But it has also been hugely rewarding, in terms of hearing about peoples’ excitement, trepidation, and progress in this space.
I ended last year, and started this year, by getting back into drawing. I managed daily sketches until around March/April, and then it dropped right off. But today, in honour of finishing up the last presentation of the year, and because I forgot to take any photos/screenshots, I thought a sketch might be a good way to mark the moment.
A sketch of a male academic presenting to a group of people. by me!
Image generated by Adobe Firefly, 3 September 2024; prompt unknown.
AI-generated media sit somewhere between representational image — representations of data rather than reality — and posthuman artefact. This ambiguous nature suggests that we need methods that not just consider these images as cultural objects, but also as products of the systems that made them. I am following here in the wake of otherpioneerswho’vebravelybrokenground in this space.
For Friedrich Kittler and Jussi Parikka, the technological, infrastructural and ecological dimensions of media are just as — if not more — important than content. They extend Marshall McLuhan’s notion that ‘the medium is the message’ from just the affordances of a given media type/form/channel, into the very mechanisms and processes that shape the content before and during its production or transmission.
I take these ideas and extend them to the outputs themselves: a media-materialist analysis. Rather than just ‘slop’, this method contends that AI media are cultural-computational artefacts, assemblages compiled from layered systems. In particular, I break this into data, model, interface, and prompt. This media materialist method contends that each step of the generative process leaves traces in visual outputs, and that we might be able to train ourselves to read them.
Data
There is no media generation without training data. These datasets can be so vast as to feel unknowable, or so narrow that they feel constricting. LAION-5B, for example, the original dataset used to train Stable Diffusion, contains 5.5 billion images. Technically, you could train a model on a handful of images, or even one, or even none, but the model would be more ‘remembering’, rather than ‘generating’. Video models tend to use smaller datasets (comparatively), such as PANDA-70M which contains over 70 million video-caption pairs: about 167,000 hours of footage.
Training data for AI models is also hugely contentious, given that many proprietary tools are trained on data scraped from the open internet. Thus, when considering datasets, it’s important to ask what kinds of images and subjects are privileged. Social media posts? Stock photos? Vector graphics? Humans? Animals? Are diverse populations represented? Such patterns of inclusion/exclusion might reveal something about the dataset design, and the motivations of those who put it together.
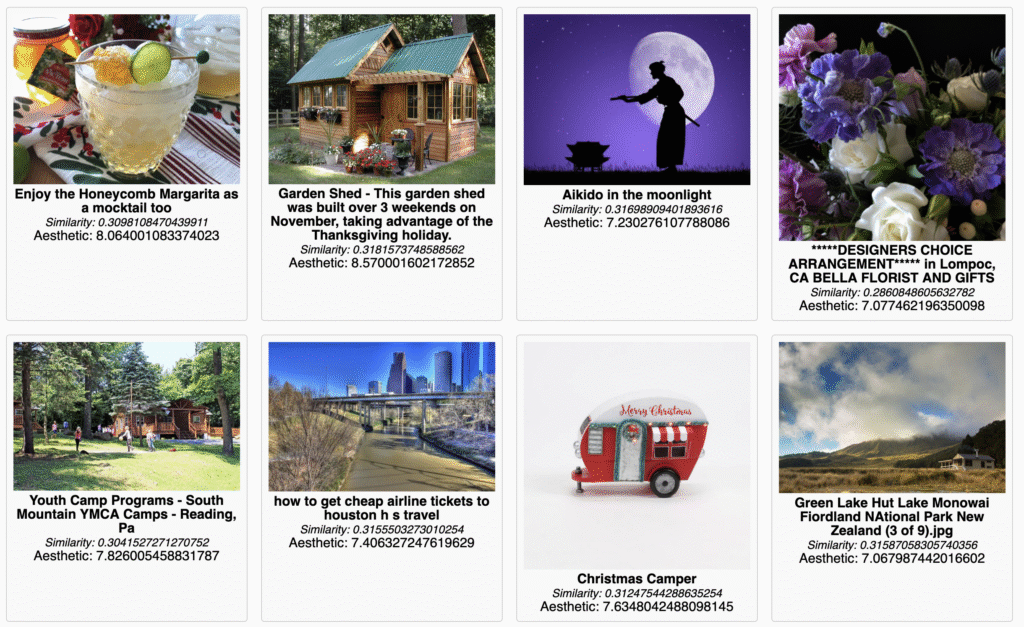
A ‘slice’ of the LAION-Aesthetics dataset. The tool I used for this can be found/forked on Github.
Some datasets are human-curated (e.g. COCO, ImageNet), and others are algorithmically scraped and compiled (e.g. LAION-Aesthetics). There may be readable differences in how these datasets shape images. You might consider:
Are the images coherent? Chaotic/glitched?
What kinds of prompts result in clearer, cleaner outputs, versus morphed or garbled material?
The dataset is the first layer where cultural logics, assumptions, patterns of normativity or exclusion are encoded in the process of media generation. So: what can you read in an image or video about what training choices have been made?
Model
The model is a program: code and computation. The model determines what happens to the training data — how it’s mapped, clustered, and re-surfaced in the generation process. This re-surfacing can influence styles, coherence, and what kinds of images or videos are possible with a given model.
If there are omissions or gaps in the training data, the model may fail to render coherent outputs around particular concepts, resulting in glitchy images, or errors in parts of a video.
Midjourney was built on Stable Diffusion, a model in active development by Stability AI since 2022. Stable Diffusion works via a process of iterative de-noising: each stage in the process brings the outputs closer to a viable, stable representation of what’s included in the user’s prompt. Leonardo.Ai’s newer Lucid models also operate via diffusion, but specialists are brought in at various stages to ‘steer’ the model in particular directions, e.g. to verify what appears as ‘photographic’, ‘artistic’, ‘vector graphic design’, and so on.
When considering the model’s imprint on images or videos, we might consider:
Are there recurring visual motifs, compositional structures, or aesthetic fingerprints?
Where do outputs break down or show glitches?
Does the model privilege certain patterns over others?
What does the model’s “best guess” reveal about its learned biases?
Analysing AI-generated media with these considerations in mind may reveal the internal logics and constraints of the model. Importantly, though, these logics and constraints will always shape AI media, whether they are readable in the outputs or not.
Interface
The interface is what the user sees when they interact with any AI system. Interfaces shape user perceptions of control and creativity. They may guide users towards a particular kind of output by making some choices easier or more visible than others.
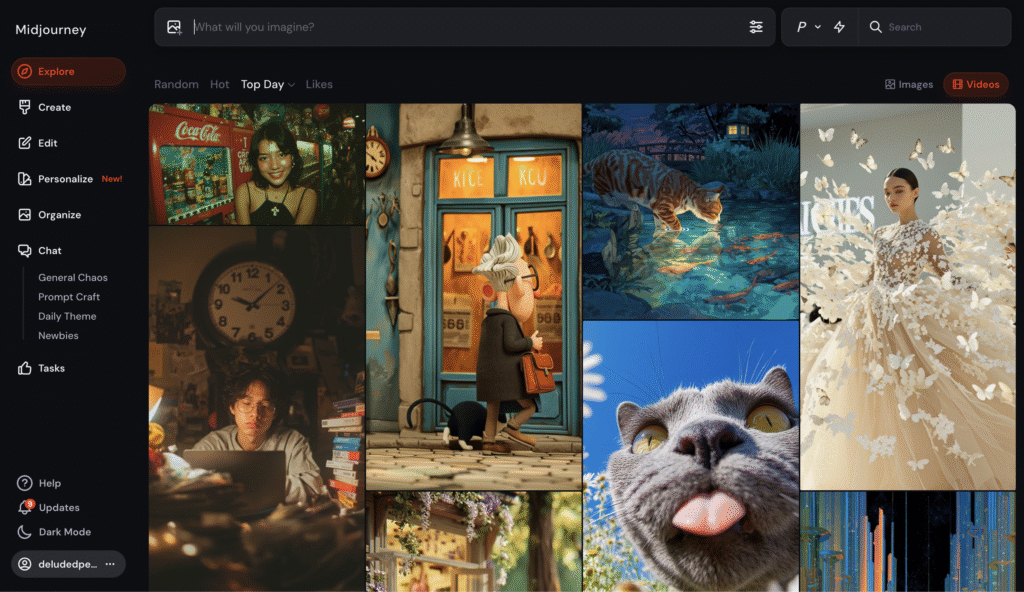
Midjourney, for example, displays a simple text box with the option to open a sub-menu featuring some more customisation options. Leonardo.Ai’s interface is more what I call a ‘studio suite’, with many controls visible initially, and plenty more available with a few menu clicks. Offline tools like DiffusionBee and ComfyUI similarly offer both simple (DiffusionBee) and complex (ComfyUI) options.
Midjourney’s web interface: ‘What will you imagine?’Leonardo.Ai’s ‘studio suite’ interface.
When looking at interfaces, consider what controls, presets, switches or sliders are foregrounded, and what is either hidden in a sub-menu or not available at all. This will give a sense of what the platform encourages: technical mastery and fine control (lots of sliders, parameters), or exploration and chance (minimal controls). Does this attract a certain kind of user? What does this tell you about the ‘ideal’ use case for the platform?
Interfaces, then, don’t just shape outputs. They also cultivate different user subjectivities: the tinkerer, the artist, the consumer.
Reading interfaces in outputs can be tricky. If the model or platform is known, one can speak of the outputs in knowledgeable terms about how the interface may have pushed certain styles, compositions, or aesthetics. But even if the platform is not known, there are some elements to speak to. If there is a coherent style, this may speak to prompt adherence or to presets embedded in the interface. Stable compositions — or more chaotic clusters of elements — may speak to a slider that was available to the user.
Whimsical or overly ‘aesthetic’ outputs often come from Midjourney. Increasingly, outputs from Kling and Leonardo are becoming much more realistic — and not in an uncanny way. But both Kling and Leonardo’s Lucid models put a plastic sheen on human figures that is recognisable.
Prompt
While some have speculated that other user input modes might be forthcoming — and others have suggested that such modes might be better — the prompt has remained the mainstay of the AI generation process, whether for text, image, video, software, or interactive environment. Some platforms say explicitly that their tools or models offer good ‘prompt adherence’, ie. what you put in is what you’ll get, but this is contingent on your putting in plausible/coherent prompts.
Prompts activate the model’s statistical associations (usually through the captions alongside the images in training embeddings), but are filtered through linguistic ambiguity and platform-specific ‘prompting grammars’.
Tools or platforms may offer options for prompt adherence or enhancement. This will push user prompts through pre-trained LLMs designed to embellish with more descriptors and pointers.
If the prompt is known, one might consider the model’s interpretation of it in the output, in terms of how literal or metaphorical the model has been. There may be notable traces of prompt conventions, or community reuse and recycling of prompts. Are there any concepts from the prompt that are over- or under-represented? If you know the model as well as the prompt, you might consider how much the model has negotiated between user intention and known model bias or default.
Even the clearest prompt is mediated by statistical mappings and platform grammars — reminding us that prompts are never direct commands, but negotiations. Thus, prompts inevitably reveal both the possibilities and limitations of natural language as an interface with generative AI systems.
Sample Analysis
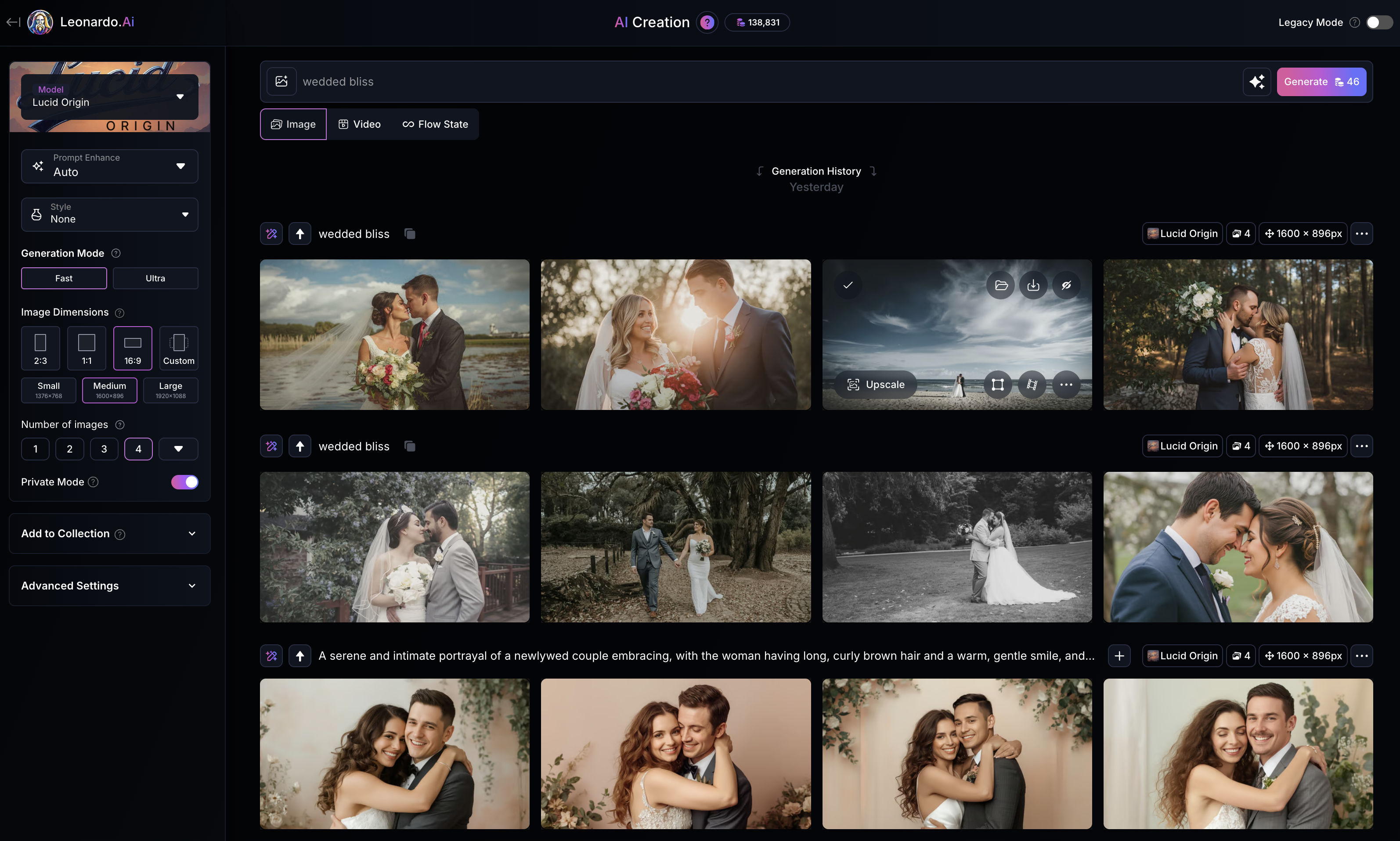
Image generated by Leonardo.Ai, 29 September 2025; prompt by me.
Prompt
‘wedded bliss’
Model
Lucid Origin
Platform
Leonardo.Ai
Prompt enhancement
off
Style preset
off
The human figures in this image are young, white, thin, able-bodied, and adhere to Western and mainstream conventions of health and wellness. The male figure has short trimmed hair and a short beard, and the female figure has long blonde hair. The male figure is taller than the female figure. They are pictured wearing traditional Western wedding garb, so a suit for the man, and a white dress with veil for the woman. Notably, all of the above was was true for each of the four generations that came out of Leonardo for this prompt. The only real difference was in setting/location, and in distance of the subjects from the ‘camera’.
By default, Lucid Origin appears to compose images with subjects in the centre of frame, and the subjects are in sharp focus, with details of the background tending to be in soft focus or completely blurred. A centered, symmetrical composition with selective focus is characteristic of Leonardo’s interface presets, which tend toward professional photography aesthetics even when presets are explicitly turned off.
The model struggles a little with fine human details, such as eyes, lips, and mouths. Notably the number of fingers and their general proportionality are much improved from earlier image generators (fingernails may be a new problem zone!). However, if figures are touching, such as in this example where the human figures are kissing, or their faces are close, the model struggles to keep shadows, or facial features, consistent. Here, for instance, the man’s nose appears to disappear into the woman’s right eye. When the subjects are at a distance, inconsistencies and errors are more noticeable.
Overall though, the clarity and confident composition of this image — and the others that came out of Leonardo with the same prompt — would suggest that a great many wedding photos, or images from commercial wedding products, are present in the training data.
Interestingly, without prompt enhancement, the model defaulted to an image presumably from the couples wedding day, as opposed to interpreting ‘wedded bliss’ to mean some other happy time during a marriage. The model’s literal interpretation here, i.e. showing the wedding day itself rather than any other moment of marital happiness, reveals how training data captions likely associate ‘wedded bliss’ (or ‘wed*’ as a wildcard term) directly with wedding imagery rather than the broader concept of happiness in marriage.
This analysis shows how attention to all four layers — data biases, model behavior, interface affordances, and prompt interpretation — reveals the ‘wedded bliss’ image as a cultural-computational artefact shaped by commercial wedding photography, heteronormative assumptions, and the technical characteristics of Leonardo’s Lucid Origin model.
This analytic method is meant as an alternative to dismissing AI media outright. To read AI images and video as cultural-computational artefacts is to recognise them as products, processes, and infrastructural traces all at once. Such readings resist passive consumption, expose hidden assumptions, and offer practical tools for interpreting the visuals that generative systems produce.
This is a summary of a journal article currently under review. In respect of the ethics of peer review, this version is much edited, heavily abridged, and the sample analysis is new specifically for this post.Once published, I will link the full article here.
For better or worse, I’m getting a bit of a reputation as ‘the AI guy’ in my immediate institutional sub-area. Depending on how charitable you’re feeling, this could be seen as very generous or wildly unfounded. I am not in any way a computer scientist or expert on emergent consciousness, synthetic cognition, language models, media generators, or even prompt engineering. I remain the same old film and media teacher and researcher I’ve always been. But I have always used fairly advanced technology as part of anything creative. My earliest memories are of typing up, decorating, and printing off books or banners or posters from my Dad’s old IBM computer. From there it was using PC laptops and desktops, and programs like Publisher or WordPerfect, 3D Movie Maker and Fine Artist, and then more media-specific tools at uni, like Final Cut and Pro Tools.
Working constantly with computers, software, and apps, automatically turns you into something of a problem-solver—the hilarious ‘joke’ of media education is that the teachers have to be only slightly quicker than their students at Googling a solution. As well as problem-solving, I am predisposed to ‘daisy-chaining’. My introduction to the term was as a means of connecting multiple devices together—on Mac systems circa 2007-2017 this was fairly standard practice thanks to the inter-connectivity of Firewire cables and ports (though I’m informed that this is still common even through USB). Reflecting back on years of software and tool usage, though, I can see how I was daisy-chaining constantly. Ripping from CD or DVD, or capturing from tape, then converting to a useable format in one program, then importing the export to another program, editing or adjusting, exporting once again, then burning or converting et cetera et cetera. Even not that long ago, there weren’t exactly ‘one-stop’ solutions to media, in the same way that you might see an app like CapCut or Instagram in that way now.
There’s also a kind of ethos to daisy-chaining. In shifting from one app, program, platform, or system, to another, you’re learning different ways of doing things, adapting your workflows each time, even if only subtly. Each interface presents you with new or different options, so you can apply a unique combination of visual, aural, and affective layers to your work. There’s also an ethos of independence: you are not locked in to one app’s way of doing things. You are adaptable, changeable, and you cherry-pick the best of what a variety of tools has to offer in order to make your work the best it can be. This is the platform economics argument, or the political platform economics argument, or some variant on all of this. Like everyone, I’ve spent many hours whinging about the time it took to make stuff or to get stuff done, wishing there was the ‘perfect app’ that would just do it all. But over time I’ve come to love my bundle of tools—the set I download/install first whenever I get a new machine (or have to wipe an old one); my (vomits) ‘stack’.
* * * * *
The above philosophy is what I’ve found myself doing with AI tools. I suppose out of all of them, I use Claude the most. I’ve found it the most straightforward in terms of setting up custom workspaces (what Claude calls ‘Projects’ and what ChatGPT calls ‘Custom GPTs’), and just generally really like the character and flavour of responses I get back. I like that it’s a little wordy, a little more academic, a little more florid, because that’s how I write and speak; though I suppose the outputs are not just encoded into the model, but also a mirror of how I’ve engaged with it. Right now in Claude I have a handful of projects set up:
Executive Assistant: Helps me manage my time, prioritise tasks, and keep me on track with work and creative projects. I’ve given it summaries of all my projects and commitments, so it can offer informed suggestions where necessary.
Research Assistant: I’ve given this most of my research outputs, as well as a curated selection of research notes, ideas, reference summaries, sometimes whole source texts. This project is where I’ll brainstorm research or teaching ideas, fleshing out concepts, building courses, etc
Creative Partner: This remains semi-experimental, because I actually don’t find AI that useful in this particular instance. However, this project has been trained on a couple of my produced media works, as well as a handful of creative ideas. I find the responses far too long to be useful, and often very tangential to what I’m actually trying to get out of it—but this is as much a project context and prompting problem as it is anything else.
2 x Course Assistants: Two projects have been trained with all the materials related to the courses I’m running in the upcoming semester. These projects are used to brainstorm course structures, lesson plans, and even lecture outlines.
Systems Assistant: This is a little different to the Executive/Research Assistants, in that it is specifically set up around ‘systems’, so the various tools, methods, workflows that I use for any given task. It’s also a kind of ‘life admin’ helper in the sense of managing information, documents, knowledge, and so on. Now that I think of it, ‘Daisy’ would probably be a great name for this project—but then again…
I will often bounce ideas, prompts, notes between all of these different projects. How much this process corrupts the ‘purity’ of each individual project is not particularly clear to me, though I figure if it’s done in an individual chat instance it’s probably not that much of an issue. If I want to make something part of a given project’s ongoing working ‘knowledge’, I’ll put a summary somewhere in its context documents.
But Claude is just one of the AI tools I use. I also have a bunch of language models on a hard drive that is always connected to my computer; I use these through the app GPT4All. These have similar functionality to Claude, ChatGPT, or any other proprietary/corporate LLM chatbot. Apart from the upper limit on their context windows, they have no usage limits; they run offline, privately, and at no cost. Their efficacy, though, is mixed. Llama and its variants are usually pretty reliable—though this is a Meta-built model, so there’s an accompanying ‘ick’ whenever I use it. Falcon, Hermes, and OpenOrca are independently developed, though these have taken quite some getting used to—I’ve also found that cloning them and training them on specific documents and with unique context prompts is the best way to use them.
With all of these tools, I frequently jump between them, testing the same prompt across multiple models, or asking one model to generate prompts for another. This is a system of usage that may seem confusing at first glance, but is actually quite fluid. The outputs I get are interesting, diverse, and useful, rather than all being of the same ‘flavour’. Getting three different summaries of the same article, for example, lets me see what different models privilege in their ‘reading’—and then I’ll know which tool to use to target that aspect next time. Using AI in this way is still time-intensive, but I’ve found it much less laborious than repeatedly hammering at a prompt in a single tool trying to get the right thing. It’s also much more enjoyable, and feels more ‘human’, in the sense that you’re bouncing around between different helpers, all of whom have different strengths. The fail-rate is thus significantly lowered.
Returning to ethos, using AI in this way feels more authentic. You learn more quickly how each tool functions, and what they’re best at. Jumping to different tools feels less like a context switch—as it might between software—and more like asking a different co-worker to weigh in. As someone who processes things through dialogue—be that with myself, with a journal, or with a friend or family member—this is a surprisingly natural way of working, of learning, and of creating. I may not be ‘the AI guy’ from a technical or qualifications standpoint, but I feel like I’m starting to earn the moniker at least from a practical, runs on the board perspective.
‘Vapourwave Hall’, generated by me using Leonardo.Ai.
This is a little late, as the article was actually released back in November, but due to swearing off work for a month over December and into the new year, I thought I’d hold off on posting here.
This piece, ‘The Allure of Artificial Worlds‘, is my first small contribution to AI research — specifically, I look here at how the visions conjured by image and video generators might be considered their own kinds of worlds. There is a nod here, as well, to ‘simulative AI’, also known as agentic AI, which many feel may be the successor to generative AI tools operating singularly. We’ll see.
Abstract
With generative AI (genAI) and its outputs, visual and aural cultures are grappling with new practices in storytelling, artistic expression, and meme-farming. Some artists and commentators sit firmly on the critical side of the discourse, citing valid concerns around utility, longevity, and ethics. But more spurious judgements abound, particularly when it comes to quality and artistic value.
This article presents and explores AI-generated audiovisual media and AI-driven simulative systems as worlds: virtual technocultural composites, assemblages of material and meaning. In doing so, this piece seeks to consider how new genAI expressions and applications challenge traditional notions of narrative, immersion, and reality. What ‘worlds’ do these synthetic media hint at or create? And by what processes of visualisation, mediation, and aisthesis do they operate on the viewer? This piece proposes that these AI worlds offer a glimpse of a future aesthetic, where the lines between authentic and artificial are blurred, and the human and the machinic are irrevocably enmeshed across society and culture. Where the uncanny is not the exception, but the rule.
So much of what I’m being fed at the moment concerns the recent wave of AI. While we are seeing something of a plateauing of the hype cycle, I think (/hope), it’s still very present as an issue, a question, an opportunity, a hope, a fear, a concept. I’ll resist my usual impulse to historicise this last year or two of innovation within the contexts of AI research, which for decades was popularly mocked and institutionally underfunded; I’ll also resist the even stronger impulse to look at AI within the even broader milieu of technology, history, media, and society, which is, apparently, my actual day job.
What I’ll do instead is drop the phrase algorithmic moment, which is what I’ve been trying to explore, define, and work through over the last 18 months. I’m heading back to work next week after an extended period of leave, so this seems as good a way of any as getting my head back into some of the research I left to one side for a while.
The algorithmic moment is what we’re in at the moment. It’s the current AI bubble, hype cycle, growth spurt, whatever you define this wave as (some have dubbed it the AI spring or boom, to distinguish it from various AI winters over the last century1). In trying to bracket it off with concrete times, I’ve settled more or less on the emergence of the GPT-3 Beta in 2020. Of course OpenAI and other AI innovations predated this, but it was GPT-3 and its children ChatGPT and DALL-E 2 that really propelled discussions of AI and its possibilities and challenges into the mainstream.
This also means that much of this moment is swept up with the COVID pandemic. While online life had bled into the real world in interesting ways pre-2020, it was really that year, during urban lockdowns, family zooms, working from home, and a deeply felt global trauma, that online and off felt one and the same. AI innovators capitalised on the moment, seizing capital (financial and cultural) in order to promise a remote revolution built on AI and its now-shunned sibling in discourse, web3 and NFTs.
How AI plugs into the web as a system is a further consideration — prior to this current boom, AI datasets in research were often closed. But OpenAI and its contemporaries used the internet itself as their dataset. All of humanity’s knowledge, writing, ideas, artistic output, fears, hopes, dreams, scraped and plugged into an algorithm, to then be analysed, searched, filtered, reworked at will by anyone.
The downfall of FTX and the trial of Sam Bankman-Fried more or less marked the death knell of NFTs as the Next Big Thing, if not web3 as a broader notion to be deployed across open-source, federated applications. And as NFTs slowly left the tech conversation, as that hype cycle started falling, the AI boom filled the void, such that one can hardly log on to a tech news site or half of the most popular Subs-stack without seeing a diatribe or puff piece (not unlike this very blog post) about the latest development.
ChatGPT has become a hit productivity tool, as well as a boon to students, authors, copy writers and content creators the world over. AI is a headache for many teachers and academics, many of whom fail not only to grasp its actual power and operations, but also how to usefully and constructively implement the technology in class activities and assessment. DALL-E, Midjourney and the like remain controversial phenomena in art and creative communities, where some hail them as invaluable aids, and others debate their ethics and value.
As with all previous revolutions, the dust will settle on that of AI. The research and innovation will continue as it always has, but out of the limelight and away from the headlines. It feels currently like we cannot keep up, that it’s all happening too fast, that if only we slowed down and thought about things, we could try and understand how we’ll be impacted, how everything might change. At the risk of historicising, exactly like I said I wouldn’t, people thought the same of the printing press, the aeroplane, and the computer. In 2002, Andrew Murphie and John Potts were trying to capture the flux and flow and tension and release of culture and technology. They were grappling in particular with the widespread adoption of the internet, and how to bring that into line with other systems and theories of community and communication. Jean-Francois Lyotard had said that new communications networks functioned largely on “language games” between machines and humans. Building on this idea, Murphie and Potts suggested that the information economy “needs us to make unexpected ‘moves’ in these games or it will wind down through a kind of natural attrition. [The information economy] feeds on new patterns and in the process sets up a kind of freedom of movement within it in order to gain access to the new.”2
The information economy has given way, now, to the platform economy. It might be easy, then, to think that the internet is dead and decaying or, at least, kind of withering or atrophying. Similarly, it can be even easier to think that in this locked-down, walled-off, platform- and app-based existence where online and offline are more or less congruent, we are without control. I’ve beendroppingbreadcrumbs over these last few posts as to how we might resist in some small way, if not to the detriment of the system, then at least to the benefit of our own mental states; and I hope to keep doing this in future posts (and over on Mastodon).
For me, the above thoughts have been gestating for a long time, but they remain immature, unpolished; unfiltered which, in its own way, is a form of resistance to the popular image of the opaque black box of algorithmic systems. I am still trying to figure out what to do with them; whether to develop them further into a series of academic articles or a monograph, to just keep posting random bits and bobs here on this site, or to seed them into a creative piece, be it a film, book, or something else entirely. Maybe a little of everything, but I’m in no rush.
As a postscript, I’m also publishing this here to resist another system, that of academic publishing, which is monolithic, glacial, frustrating, and usually hidden behind a paywall for a privileged few. Anyway, I’m not expecting anyone to read this, much less use or cite it in their work, but better it be here if someone needs it than reserved for a privileged few.
As a bookend for the AI-generated image that opened the post, I asked Bard for “a cool sign-off for my blog posts about technology, history, and culture” and it offered the following, so here you go…
Signing off before the robots take over. (Just kidding… maybe.)
Notes
For an excellent history of AI up to around 1990, I can’t recommend enough AI: The Tumultuous History of the Search for Artificial Intelligence by Daniel Crevier. Crevier has made the book available for download via ResearchGate. ↩︎