Daniel Binns is a media theorist and filmmaker tinkering with the weird edges of technology, storytelling, and screen culture. He is the author of Material Media-Making in the Digital Age and currently writes about posthuman poetics, glitchy machines, and speculative media worlds.
Image generated by Leonardo.Ai, 6 November 2025; prompt by me.
My work on and with generative AI continues apace, but I’m presently in a bit of a reflection and consolidation phase. One of the notions that’s popped up or out or through is that of generativity. Definitely not a dictionary word, but it emerged from — of all places — psychoanalysis. Specifically, it was used by a German-American psychoanalyst and artist named Erik Erikson. Erikson’s primary research focus was psychosocial development, and ‘generativity’ was the term he applied to “the concern in establishing and guiding the next generation” (source: p. 267).
My adoption of the term is in some ways adjacent, in the sense of a property of tools or systems that ‘help’ by generating choices, solutions, or possibilities. In this sense, generativity is also a practice and concept in and of itself. Generative artificial intelligence is, of course, one example of a technology possessing generativity, but I’ve also been thinking a lot about generative art (be it digital/code-based, or driven by analogue tools or naturally occurring randomness), generative design, procedural generation, mathematical/computational models of chance and probability, as well as lo-fi tools and processes: think dice, tarot cards, or roll tables in TTRPGs.
The name I’ve given my repeatable genAI experiments is ‘ritual-technic‘. These are designed specifically as recipes for generativity (one example here). Primarily, this is to allow some kind of exploration or understanding of the technology’s capabilities or limitations. They may also produce content that is useful: research fodder to unpack or analyse, or glitchy outputs that I can remix creatively. But another potential output is a protocol for generativity itself. One the one hand, these protocols can be rich in terms of understanding how LLMs conceive of creativity, human action, and the ‘real’ world. But on the other, they push users off the model, and into a generative mode themselves. These protocols are a kind of genAI costume you can put on, to try out being a generative thing yourself.
Another quality of the ritual-technic is that it will often test not just the machine, but the user. These are rituals, practices, bounded activities, that may occasion some strange feelings: uncertainty, confusion, delight, fear. These feelings shouldn’t be quashed or ignored, they should be observed, marked, noted, and tracked. Our subjective experience of using technology, particularly those like genAI that are opaque, complex, or ideologically-loaded, is the embodiment, the lived and felt experience, of our ethics and values. Many of my experiments have emerged as a way of learning about genAI in a way that feels engaging, relevant, and fun — yes! fun! what a concept! But as I’ve noted elsewhere, the feelings accompanying this work aren’t always comfortable. It’s always a reckoning: with my own creativity, capabilities, limitations, and with my willingness to accept assistance or outsource tasks to the unknown.
For Erikson, generativity was about nurturing the future. I think mine is more about figuring out what future we’re in, or what future I want to shape for myself. Part of this is finding ways to understand the systems that are influencing the world around us, and part of it is deciding when to take control, to accept control, or when to let it go. Generativity is, at least in my definition and understanding, innately about ceding some kind of control. You might be handing one of the reins to a D6 or a card draw, to a writing prompt or a creative recipe, or to a machine. In so doing, you open yourself to chance, to the unexpected, to the chaos, where fun or fear are just a coin flip away.
K1no looks… friendly. Image generated by Leonardo.Ai, 14 October 2025; prompt by me.
Notes from a GenAI Filmmaking Sprint
AI video swarms the internet. It’s been around for nearly as long as AI-generated images, however its recent leaps and bounds in terms of realism, efficiency, and continuity have made it a desirable medium for content farmers, slop-slingers, and experimentalists. That said, there are those who are deploying the newer tools to hint at new forms of media, narrative, and experience.
I was recently approached by the Disrupt AI Film Festival, which will run in Melbourne in November. As well as micro and short works (up to 3 mins and 3-15 mins respectively), they also have a student category in need of submissions. So over the last few weeks I organised a GenAI filmmaking Sprint at RMIT University last Friday. Leonardo.Ai was generous enough to donate a bunch of credits for us to play with, and also beamed in to give us a masterclass in how to prompt to generate AI video for storytelling — rather than just social media slurry.
Movie magic? Participants during the GenAI Filmmaking Sprint at RMIT University, 10 October 2025.
I also shared some thoughts from myresearch in terms of what kinds of stories or experiences work well for AI video, and also some practical insights on how to develop and ‘write’ AI films. The core of the workshop as a whole was to propose a structured approach: move from story ideas/fragments to logline, then to beat sheet, then shot list. The shot list, then, can be adapted slightly into the parlance of whatever tool you’re using to generate your images — you then end up with start frames for the AI video generator to use.
This structure from traditional filmmaking functions as a constraint. But with tools that can, in theory, make anything, constraints are needed more than ever. The results were glimpses of shots that embraced both the impossible, fantastical nature of AI video, while anchoring it with characters, direction, or a particular aesthetic.
In the workshop, I remembered moments in my studio Augmenting Creativity where students were tasked with using AI tools: particularly in the silences. Working with AI — even when it is dynamic, interesting, generative, fruitful, fun — is a solitary endeavour. AI filmmaking, too, in a sense, is a stark contrast to the hectic, chaotic, challenging, but highly dynamic and collaborative nature of real-life production. This was a reminder, and a timely one, that in teaching AI (as with any technology or tool), we must remember three turns that students must make: turn to the tool, turn to each other, turn to the class. These turns — and the attendant reflection, synthesis, and translation required with each — is where the learning and the magic happens.
This structured approach helpfully supported and reiterated some of my thoughts on the nature of AI collaboration itself. I’ve suggested previously that collaborating with AI means embracing various dynamics — agency, hallucination, recursion, fracture, ambience. This workshop moved away — notably, for me andmypredilections — from glitch, from fracture or breakage and recursion. Instead, the workflow suggested a more stable, more structured, more intentional approach, with much more agency on the part of the human in the process. The ambience, too, was notable, in how much time is required for the labour of both human and machine: the former in planning, prompting, managing shots and downloaded generations; the latter in processing the prompts, generating the outputs.
Video generated for my AI micro-film The Technician (2024).
What remains with me after this experience is a glimpse into creative genAI workflows that are more pragmatic, and integrated with other media and processes. Rather than, at best, unstructured open-ended ideation or, at worst, endless streams of slop, the tools produce what we require, and we use them to that end, and nothing beyond that. This might not be the radical revelation I’d hoped for, but it’s perhaps a more honest account of where AI filmmaking currently sits — somewhere between tool and medium, between constraint and possibility.
Image generated by Adobe Firefly, 3 September 2024; prompt unknown.
AI-generated media sit somewhere between representational image — representations of data rather than reality — and posthuman artefact. This ambiguous nature suggests that we need methods that not just consider these images as cultural objects, but also as products of the systems that made them. I am following here in the wake of otherpioneerswho’vebravelybrokenground in this space.
For Friedrich Kittler and Jussi Parikka, the technological, infrastructural and ecological dimensions of media are just as — if not more — important than content. They extend Marshall McLuhan’s notion that ‘the medium is the message’ from just the affordances of a given media type/form/channel, into the very mechanisms and processes that shape the content before and during its production or transmission.
I take these ideas and extend them to the outputs themselves: a media-materialist analysis. Rather than just ‘slop’, this method contends that AI media are cultural-computational artefacts, assemblages compiled from layered systems. In particular, I break this into data, model, interface, and prompt. This media materialist method contends that each step of the generative process leaves traces in visual outputs, and that we might be able to train ourselves to read them.
Data
There is no media generation without training data. These datasets can be so vast as to feel unknowable, or so narrow that they feel constricting. LAION-5B, for example, the original dataset used to train Stable Diffusion, contains 5.5 billion images. Technically, you could train a model on a handful of images, or even one, or even none, but the model would be more ‘remembering’, rather than ‘generating’. Video models tend to use smaller datasets (comparatively), such as PANDA-70M which contains over 70 million video-caption pairs: about 167,000 hours of footage.
Training data for AI models is also hugely contentious, given that many proprietary tools are trained on data scraped from the open internet. Thus, when considering datasets, it’s important to ask what kinds of images and subjects are privileged. Social media posts? Stock photos? Vector graphics? Humans? Animals? Are diverse populations represented? Such patterns of inclusion/exclusion might reveal something about the dataset design, and the motivations of those who put it together.
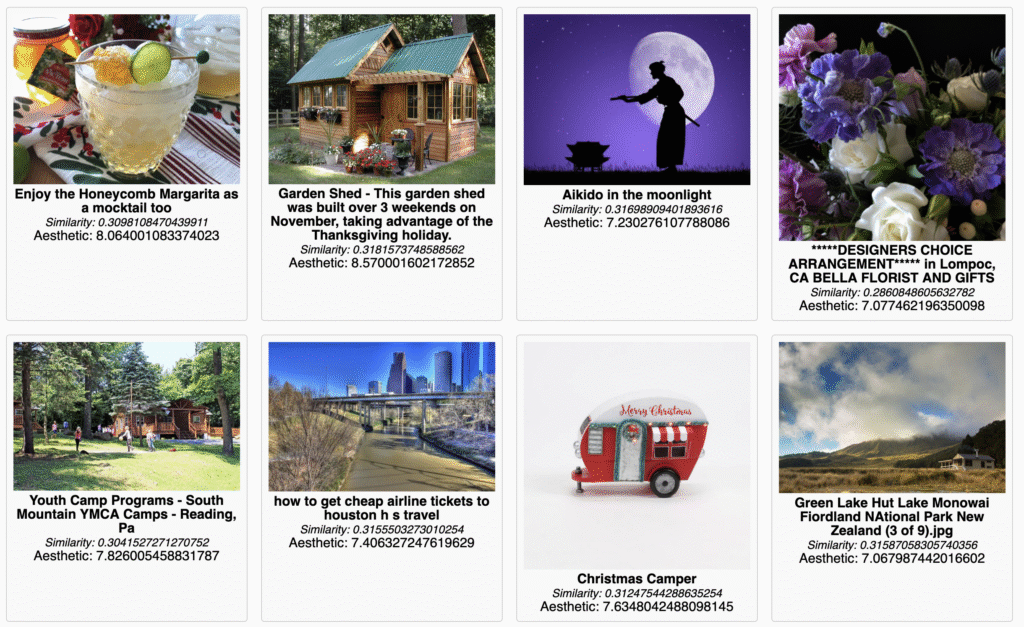
A ‘slice’ of the LAION-Aesthetics dataset. The tool I used for this can be found/forked on Github.
Some datasets are human-curated (e.g. COCO, ImageNet), and others are algorithmically scraped and compiled (e.g. LAION-Aesthetics). There may be readable differences in how these datasets shape images. You might consider:
Are the images coherent? Chaotic/glitched?
What kinds of prompts result in clearer, cleaner outputs, versus morphed or garbled material?
The dataset is the first layer where cultural logics, assumptions, patterns of normativity or exclusion are encoded in the process of media generation. So: what can you read in an image or video about what training choices have been made?
Model
The model is a program: code and computation. The model determines what happens to the training data — how it’s mapped, clustered, and re-surfaced in the generation process. This re-surfacing can influence styles, coherence, and what kinds of images or videos are possible with a given model.
If there are omissions or gaps in the training data, the model may fail to render coherent outputs around particular concepts, resulting in glitchy images, or errors in parts of a video.
Midjourney was built on Stable Diffusion, a model in active development by Stability AI since 2022. Stable Diffusion works via a process of iterative de-noising: each stage in the process brings the outputs closer to a viable, stable representation of what’s included in the user’s prompt. Leonardo.Ai’s newer Lucid models also operate via diffusion, but specialists are brought in at various stages to ‘steer’ the model in particular directions, e.g. to verify what appears as ‘photographic’, ‘artistic’, ‘vector graphic design’, and so on.
When considering the model’s imprint on images or videos, we might consider:
Are there recurring visual motifs, compositional structures, or aesthetic fingerprints?
Where do outputs break down or show glitches?
Does the model privilege certain patterns over others?
What does the model’s “best guess” reveal about its learned biases?
Analysing AI-generated media with these considerations in mind may reveal the internal logics and constraints of the model. Importantly, though, these logics and constraints will always shape AI media, whether they are readable in the outputs or not.
Interface
The interface is what the user sees when they interact with any AI system. Interfaces shape user perceptions of control and creativity. They may guide users towards a particular kind of output by making some choices easier or more visible than others.
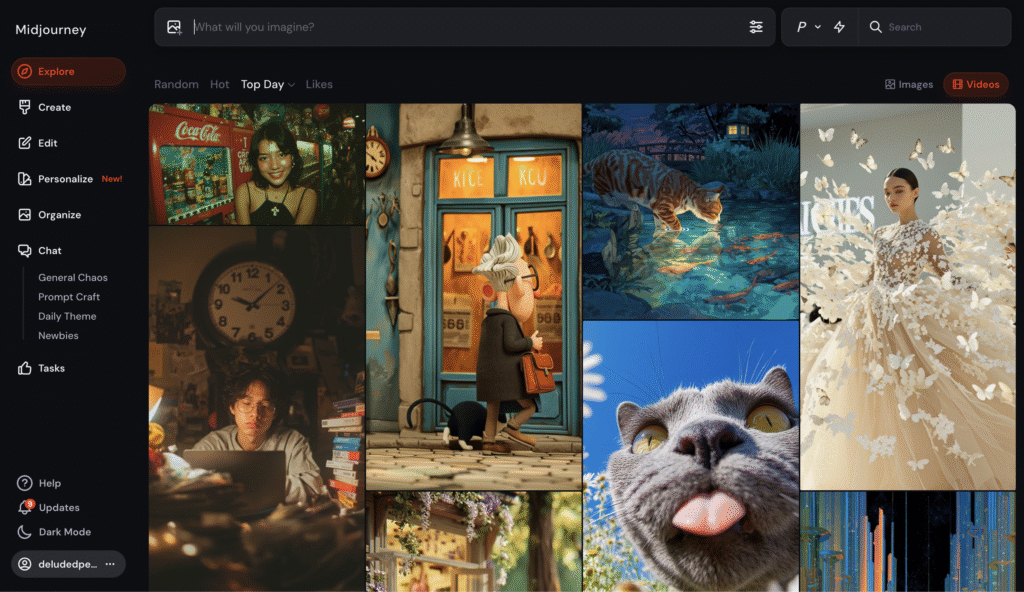
Midjourney, for example, displays a simple text box with the option to open a sub-menu featuring some more customisation options. Leonardo.Ai’s interface is more what I call a ‘studio suite’, with many controls visible initially, and plenty more available with a few menu clicks. Offline tools like DiffusionBee and ComfyUI similarly offer both simple (DiffusionBee) and complex (ComfyUI) options.
Midjourney’s web interface: ‘What will you imagine?’Leonardo.Ai’s ‘studio suite’ interface.
When looking at interfaces, consider what controls, presets, switches or sliders are foregrounded, and what is either hidden in a sub-menu or not available at all. This will give a sense of what the platform encourages: technical mastery and fine control (lots of sliders, parameters), or exploration and chance (minimal controls). Does this attract a certain kind of user? What does this tell you about the ‘ideal’ use case for the platform?
Interfaces, then, don’t just shape outputs. They also cultivate different user subjectivities: the tinkerer, the artist, the consumer.
Reading interfaces in outputs can be tricky. If the model or platform is known, one can speak of the outputs in knowledgeable terms about how the interface may have pushed certain styles, compositions, or aesthetics. But even if the platform is not known, there are some elements to speak to. If there is a coherent style, this may speak to prompt adherence or to presets embedded in the interface. Stable compositions — or more chaotic clusters of elements — may speak to a slider that was available to the user.
Whimsical or overly ‘aesthetic’ outputs often come from Midjourney. Increasingly, outputs from Kling and Leonardo are becoming much more realistic — and not in an uncanny way. But both Kling and Leonardo’s Lucid models put a plastic sheen on human figures that is recognisable.
Prompt
While some have speculated that other user input modes might be forthcoming — and others have suggested that such modes might be better — the prompt has remained the mainstay of the AI generation process, whether for text, image, video, software, or interactive environment. Some platforms say explicitly that their tools or models offer good ‘prompt adherence’, ie. what you put in is what you’ll get, but this is contingent on your putting in plausible/coherent prompts.
Prompts activate the model’s statistical associations (usually through the captions alongside the images in training embeddings), but are filtered through linguistic ambiguity and platform-specific ‘prompting grammars’.
Tools or platforms may offer options for prompt adherence or enhancement. This will push user prompts through pre-trained LLMs designed to embellish with more descriptors and pointers.
If the prompt is known, one might consider the model’s interpretation of it in the output, in terms of how literal or metaphorical the model has been. There may be notable traces of prompt conventions, or community reuse and recycling of prompts. Are there any concepts from the prompt that are over- or under-represented? If you know the model as well as the prompt, you might consider how much the model has negotiated between user intention and known model bias or default.
Even the clearest prompt is mediated by statistical mappings and platform grammars — reminding us that prompts are never direct commands, but negotiations. Thus, prompts inevitably reveal both the possibilities and limitations of natural language as an interface with generative AI systems.
Sample Analysis
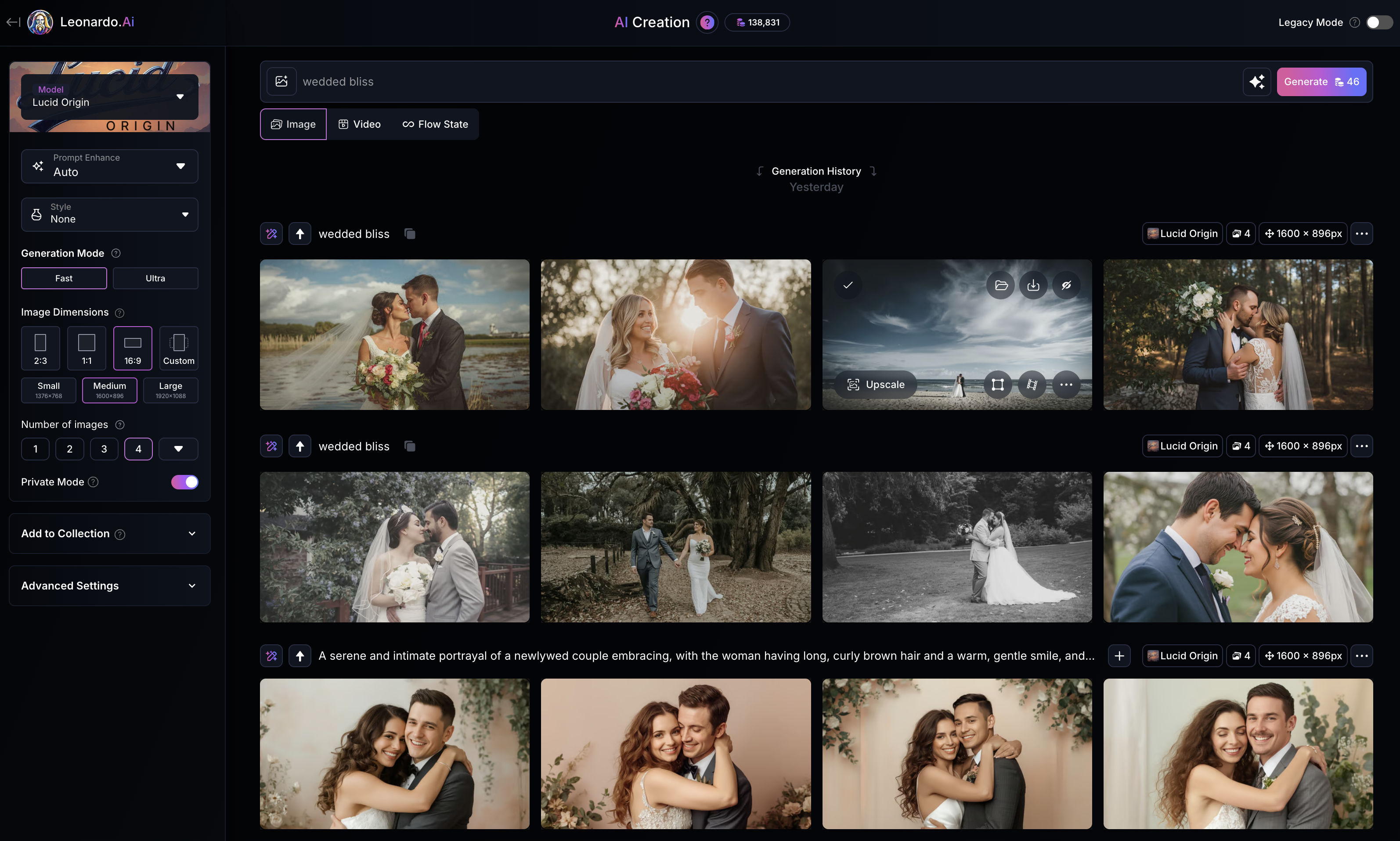
Image generated by Leonardo.Ai, 29 September 2025; prompt by me.
Prompt
‘wedded bliss’
Model
Lucid Origin
Platform
Leonardo.Ai
Prompt enhancement
off
Style preset
off
The human figures in this image are young, white, thin, able-bodied, and adhere to Western and mainstream conventions of health and wellness. The male figure has short trimmed hair and a short beard, and the female figure has long blonde hair. The male figure is taller than the female figure. They are pictured wearing traditional Western wedding garb, so a suit for the man, and a white dress with veil for the woman. Notably, all of the above was was true for each of the four generations that came out of Leonardo for this prompt. The only real difference was in setting/location, and in distance of the subjects from the ‘camera’.
By default, Lucid Origin appears to compose images with subjects in the centre of frame, and the subjects are in sharp focus, with details of the background tending to be in soft focus or completely blurred. A centered, symmetrical composition with selective focus is characteristic of Leonardo’s interface presets, which tend toward professional photography aesthetics even when presets are explicitly turned off.
The model struggles a little with fine human details, such as eyes, lips, and mouths. Notably the number of fingers and their general proportionality are much improved from earlier image generators (fingernails may be a new problem zone!). However, if figures are touching, such as in this example where the human figures are kissing, or their faces are close, the model struggles to keep shadows, or facial features, consistent. Here, for instance, the man’s nose appears to disappear into the woman’s right eye. When the subjects are at a distance, inconsistencies and errors are more noticeable.
Overall though, the clarity and confident composition of this image — and the others that came out of Leonardo with the same prompt — would suggest that a great many wedding photos, or images from commercial wedding products, are present in the training data.
Interestingly, without prompt enhancement, the model defaulted to an image presumably from the couples wedding day, as opposed to interpreting ‘wedded bliss’ to mean some other happy time during a marriage. The model’s literal interpretation here, i.e. showing the wedding day itself rather than any other moment of marital happiness, reveals how training data captions likely associate ‘wedded bliss’ (or ‘wed*’ as a wildcard term) directly with wedding imagery rather than the broader concept of happiness in marriage.
This analysis shows how attention to all four layers — data biases, model behavior, interface affordances, and prompt interpretation — reveals the ‘wedded bliss’ image as a cultural-computational artefact shaped by commercial wedding photography, heteronormative assumptions, and the technical characteristics of Leonardo’s Lucid Origin model.
This analytic method is meant as an alternative to dismissing AI media outright. To read AI images and video as cultural-computational artefacts is to recognise them as products, processes, and infrastructural traces all at once. Such readings resist passive consumption, expose hidden assumptions, and offer practical tools for interpreting the visuals that generative systems produce.
This is a summary of a journal article currently under review. In respect of the ethics of peer review, this version is much edited, heavily abridged, and the sample analysis is new specifically for this post.Once published, I will link the full article here.
This semester I’m running a Media studio called ‘Augmenting Creativity’. The basic goal is to develop best practices for working with generative AI tools not just in creative workflows, but as part of university assignments, academic research, and in everyday routines. My motivation or philosophy for this studio is that so much attention is being focused on the outputs of tools like Midjourney and Leonardo.Ai (as well as outputs from textbots like ChatGPT); what I guess I’m interested in is exploring more precisely where in workflows, jobs, and daily life that these tools might actually be helpful.
In class last week we held a Leonardo.Ai hackathon, inspired by one of the workshops that was run at the Re/Framing AI event I convened a month or so ago. Leonardo.Ai generously donated some credits for students to play around with the platform. Students were given a brief around what they should try to generate:
an AI Self-Portrait (using text only; no image guidance!)
three images to envision the studio as a whole (one conceptual, a poster, and a social media tile)
three square icons to represent one task in their daily workflow (home, work, or study-related)
For the Hackathon proper, students were only able to adjust the text prompt and the Preset Style; all other controls had to remain unchanged, including the Model (Phoenix), Generation Mode (Fast), Prompt Enhance (off), and all others.
Students were curious and excited, but also faced some challenges straight away with the underlying mechanics of image generators; they had to play around with word choice in prompts to get close to desired results. The biases and constraints of the Phoenix model quickly became apparent as the students tested its limitations. For some students this was more cosmetic, such as requesting that Leonardo.Ai generate a face with no jewelry or facial hair. This produced mixed results, in that sometimes explicitly negative prompts seemed to encourage the model to produce what wasn’t wanted. Other students encountered difficulties around race or gender presentation: the model struggles a lot with nuances in race, e.g. mixed-race or specific racial subsets, and also often depicts sexualised presentations of female-presenting people (male-presenting too, but much less frequently).
This session last week proved a solid test of Leonardo.Ai’s utility and capacity in generating assets and content (we sent some general feedback to Leonardo.Ai on platform useability and potential for improvement), but also was useful for figuring out how and where the students might use the tool in their forthcoming creative projects.
This week we’ve spent a little time on the status of AI imagery as art, some of the ethical considerations around generative AI, and where some of the supposed impacts of these tools may most keenly be felt. In class this morning, the students were challenged to deliver lightning talks on recent AI news, developing their presentation and media analysis skills. From here, we move a little more deeply into where creativity lies in the AI process, and how human/machine collaboration might produce innovative content. The best bit, as always, will be seeing where the students go with these ideas and concepts.